
A group of students are stacked according to their heights. The result resembles a normal bell curve.

Figure 1 – Normal Bell Curve of Heights of Students (found here)
Who are the students in the picture? The image is from the statistics and actuarial science department of Simon Fraser University. These students are likely from this university (either from the statistics department or from other areas). Beyond the assumption of being students in a Canadian university, we do not know much else about the students.
There are 46 students in the picture. All students with the same height stand in the same column with the first student in a column holding a sign stating the height. The signs are in ascending order from left to right. This formation of the students according to heights resembles a normal bell curve. Most of the students cluster in the middle with very few students at either the left tail (short students) or the right tail (tall students). This is a clever demonstration of the normal bell curve. It is relatively easy to create – basically ranking the students according to heights. It is an excellent opportunity to discuss the properties of normal bell curve.
Interestingly male and female students are mixed together. It appears that female students are mostly standing to the left of the center and male students on the right. The discussion would be even more meaningful if the students are grouped by gender (in two separate photos). In any case, we work with the photo as is. The following is the same stacking of the students with the students represented by dots.

Figure 2 – stacking of dots to represent the same bell curve
Figure 2 (a dot plot) actually gives a lot more clarity on the shape of the curve. The curve is not perfectly symmetric, though the overall shape resembles a bell curve. The curve is not “smooth” as there is depression in some places (e.g. at 5′ 3″, 5′ 5″ and 5′ 10″). Perhaps the “rough” curve is due to the mixing of two populations (males and females) or perhaps due to the small sample size. The curve appears sufficiently close to a normal bell curve to warrant a closer look.
The dot plot in Figure 2 actually gives the sample data. Let’s perform calculations on the sample data. Particularly we focus on calculations that can confirm whether the curve is a normal bell curve (at least whether we should reject the notion that it is a normal bell curve). If there is reason to believe that the heights of university students are normally distributed (or approximately normally distributed), the normal model can be useful for making estimations. We give a few examples to demonstrate how this is done.
First, calculate the mean and the median of the height measurements. The mean is 66.78 inches and the median is 67 inches. The mean is simply the sum of all the measurements divided by the total number of data points. The median is the measurement that is in the middle if the measurements are ranked in ascending order, which is the case in Figure 2. The mean and median are very close – indication that the height measurements form a symmetric distribution.
Another check is to see whether the height measurements follow the empirical rule (also known as the 68-95-99.7 rule). Here’s the rule.
- About 68% of the data will fall within plus or minus one standard deviation of the mean.
- About 95% of the data will fall within plus or minus two standard deviations of the mean.
- About 99.7% of the data will fall within plus or minus three standard deviations of the mean.
To verify these three points, we need to calculation the standard deviation of the height sample data. The sample standard deviation of height measurements is 3.37 inches. Here’s the three intervals of interest.
- (66.78 – 1 x 3.37, 66.78 + 1 x 3.37)=(63.41, 70.15)
- (66.78 – 2 x 3.37, 66.78 + 2 x 3.37)=(60.04, 73.52)
- (66.78 – 3 x 3.37, 66.78 + 3 x 3.37)=(56.67, 76.89)
The question is, how many of the 46 height measurements fall into each interval? For example, how many of the measurements are between 63.41 and 70.15 inches? Is the percentage close to 68? Here’s the counts.
- 30 measurements in (63.41, 70.15). Percentage = 30/46 = 65.2%
- 45 measurements in (60.04, 73.52). Percentage = 45/46 = 97.8%
- 46 measurements in (56.67, 76.89). Percentage = 46/46 = 100%
These percentages are off from the 68-95-99.7 rule, but are close enough. Of course, the percentages from the data do not have to match the 68-95-99.7 rule exactly in order to conclude that the distribution is normal. Because the actual percentages of 65-.2-97.8-100 are close enough, there is no reason to believe that the height measurements of university students is not a normal bell curve.
Once we know that the height measurements of people in a certain population (university students in this case) shape like a normal bell curve, we can use the bell curve to estimate proportion of the population that fall into a given interval. This is one advantage of working with a normal distribution.
Based on the above discussion, we conclude that the height measurements of university students follow an approximate normal distribution with mean 66.78 inches and standard deviation 3.37 inches. With this information, we can make estimation.
For example, what is the proportion (or percentage) of university students whose heights are less than or equal to 70 inches?
The key to answering the question is to convert the height measurement of 70 inches into a standardized score (or z-score), which in this case is 0.96. The z-score is obtained by this calculation: z=(70 – 66.78)/3.37 = 0.96 (rounded to two decimal points). Then we can look up the z-score 0.96 in a normal table to obtain the probability 0.8315. We conclude that about 83.15% of university students are 70 inches or shorter. To look up 0.8315, use a normal table that is similar to the one found here. Looking up normal probability using a calculator will yield slightly different answer.
Another example. What is the probability that a randomly selected university student is between 64 inches (5 feet 4 inches) and 70 inches (5 feet 10 inches) tall?
First, turn the measurements of 64 inches and 70 inches into standardized scores (z-scores). The z-score of 70 inches is 0.96 (as calculated above). The z-score of 64 inches is (64 – 66.78)/3.37 = -0.82 (rounded to two decimal places). The probability of the z-score of -0.82 is 1 – 0.7939 = 0.2061. Note that the table in the link has no negative z-scores. So look up the z-score of 0.82, which gives 0.7939. Then subtract 0.7939 into 1 gives 0.2061. Then the answer to the question is 0.8315 – 0.2061 = 0.6254. This tells us that about 62.54% of the time, a randomly selected university student is between 64 and 70 inches tall.
One more example, what is the proportion of university students taller than 6 feet (72 inches)?
The z-score of 72 inches is (72 – 66.78)/3.37 = 1.55. Looking up the table, the probability is 0.9394. This would be the probability of less than 70 inches. So the answer is 1 – 0.9394 = 0.0606. About 6% of the university students is 6 feet tall or taller. If the size of the student body is 10,000, then there are about 600 students who are 6 feet or taller.
Here’s a few previous posts on normal distribution.
- A student’s view of the normal distribution
- An example of a normal curve
- The middle 80% is not 80th percentile
- Interpreting ACT scores
Comments about Calculation
To calculate the mean and median as well as standard deviation of the height measurements, we should use a statistical calculator (or software) if possible. If the goal is to compute using basic principle, the mean is of course the sum of the data points divided by the total number of data points. In this example, sum all the 46 height measurements and then divide the sum by 46.
To find the median height measurement, rank the measurements from smallest to the largest. The measurements shown in Figure 2 are already ranked. Locate the 23rd measurement and the 24th measurement. The median would be the average of these two measurements. Since they are the same (67 inches), the median height measurement is 67 inches.
To find the standard deviation of the height measurements, use a calculator with statistical functions. To calculate without using a statistical calculator, first calculate the sample variance. Then take square root of the sample variance. The following is how the variance is calculated (this is best done in a spreadsheet or other software).

The idea is to take the difference between each measurement and the mean 66.78 and then square the difference. Do this for each of the 46 measurements. Sum these 46 squared difference. Then divide the sum by 45 (one less than 46). This adjustment of dividing by one less than the sample size is to sample variance an unbiased estimator of the population variance.
The sample standard deviation is the square root of 11.3792. Thus the standard deviation of the height measurements is 

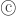

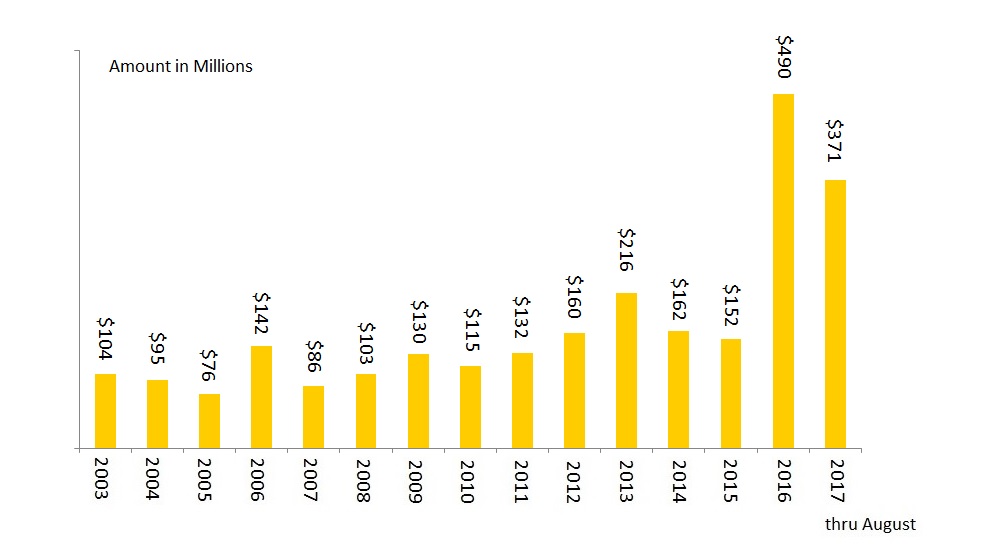
 units of wealth between the two players, with player A owning
units of wealth between the two players, with player A owning  units and player B owning
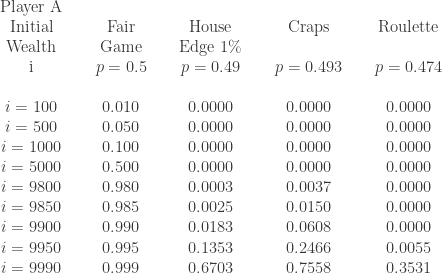
units and player B owning  units. In each play of the game, a coin is tossed. If the result of the coin toss is a head, player A collect 1 unit from player B. If the result of the coin toss is a tail, player A pays player B 1 unit. What is the probability that player A ends up with all the
units. In each play of the game, a coin is tossed. If the result of the coin toss is a head, player A collect 1 unit from player B. If the result of the coin toss is a tail, player A pays player B 1 unit. What is the probability that player A ends up with all the  . The long run probability of player B winning all the units is
. The long run probability of player B winning all the units is  .
. with
with 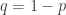 . Suppose further that player A owns
. Suppose further that player A owns  . The long run probability of player B winning all the units is
. The long run probability of player B winning all the units is 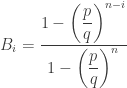 .
. = 0.51 with
= 0.51 with 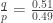 = 1.040816327. Let’s say the total initial wealth is 100 units and player A owns 10 units at the beginning. Then
= 1.040816327. Let’s say the total initial wealth is 100 units and player A owns 10 units at the beginning. Then  is the following:
is the following: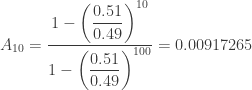
 instead of
instead of  . In the numerator,
. In the numerator, 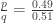 to obtain
to obtain 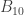 = 0.99082735. There is more than 99% chance that player B (the house) will own all 100 units.
= 0.99082735. There is more than 99% chance that player B (the house) will own all 100 units.  equals 1.0. In fact,
equals 1.0. In fact, 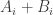 is always 1.0. Thus
is always 1.0. Thus  can be calculated by
can be calculated by  . In other words, the probability of breaking the bank plus the probability of ruin is always 1.0. When a gambler plays at a casino, there are only two possibilities, either breaking the bank or ruin. There is no third possibility, e.g. the game goes indefinitely with no winner.
. In other words, the probability of breaking the bank plus the probability of ruin is always 1.0. When a gambler plays at a casino, there are only two possibilities, either breaking the bank or ruin. There is no third possibility, e.g. the game goes indefinitely with no winner.
 and
and 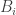 only provide the long run probability for player A (the gambler) to break the bank and the long run probability of ruin for player A, respectively. They give no information about the number of plays of the game in order to reach the eventual success or ruin.
only provide the long run probability for player A (the gambler) to break the bank and the long run probability of ruin for player A, respectively. They give no information about the number of plays of the game in order to reach the eventual success or ruin. 
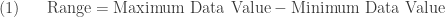
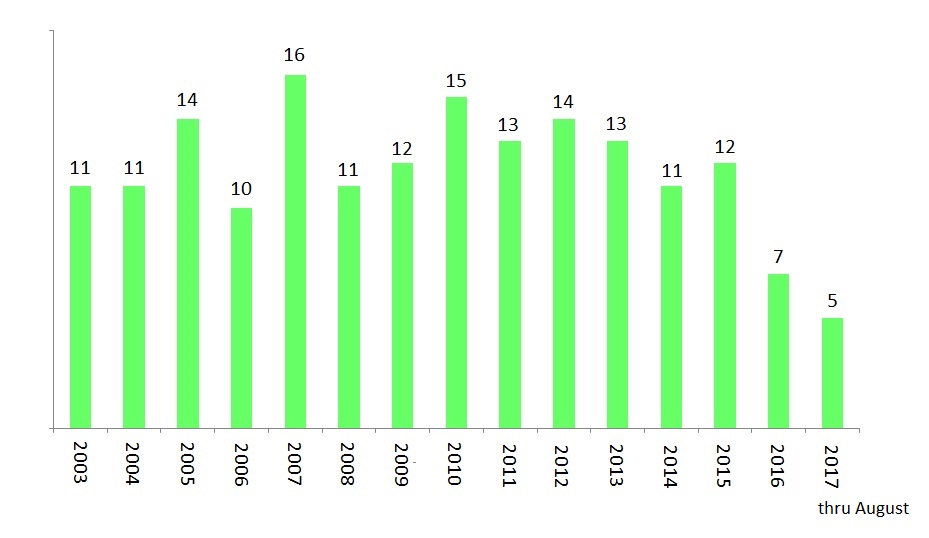
 is simply the length of the interval from the smallest data value to the largest data value. We do not know exactly what the largest household income is. So we assume it is the household of Bill Gates ($7.8 billion is a number we found on the Internet). So the range of annual household incomes is about $7.8 billion (all the way from an amount near $0 to $7.8 billion).
is simply the length of the interval from the smallest data value to the largest data value. We do not know exactly what the largest household income is. So we assume it is the household of Bill Gates ($7.8 billion is a number we found on the Internet). So the range of annual household incomes is about $7.8 billion (all the way from an amount near $0 to $7.8 billion).
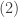 below and in the following figure.
below and in the following figure.

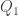 ) to the third quartile (
) to the third quartile ( ) contains the middle 50% of the data. The interquartile range (IQR) is defined to be the length of this interval. The IQR is computed as in the following:
) contains the middle 50% of the data. The interquartile range (IQR) is defined to be the length of this interval. The IQR is computed as in the following:














Food scientists need to make sense of numbers
Food – the part of the economy that encompasses the production, the processing and the marketing of foods – is big business. In fact, the successes of the food industry depend in no small measure on the use of statistics. For example, the scientists in a food company need to understand and measure the sensory quality of foods. They want you to spend more and eat more. One of the ways to do that is to produce the food products that tickle and entice as many of the senses as possible.
Two short courses (one-day and two-day) offered by the Food Science Department at Rutgers University give some clues on the statistics used in food science. Here’s the link to the short courses (statistics and sensory evaluation). Just in case the links are broken or removed in the future, here’s the screen shots for the course descriptions.
Course: Statistics for Food Science

The above screen shot is the description of a statistics course called Statistics for Food Science. The topics are basic statistics topics that are applicable in many disciplines and industries. It is clear that the course will be tailored to the food industry. The broad goal of the course is to help scientists and specialists in the food industry to properly design and carry out experiments and to make sense of the data produced in the experiments and other studies.
There are 7 bullet points for the subjects/topics discussed in the course. All of them are useful topics. In fact, some of these topics are even touched on in some level in an introductory stats course. For example, the first bullet point is on descriptive statistics – using numerical measures and graphical summaries to make sense of data. An introductory course touches on regression and sampling distribution theory (at least superficially). For example, simple regression (one explanatory variable and one response variable) and one-variable sampling theory involving normal distribution are covered in an introductory stats course. Basic concepts in experimental design are covered too in an introductory course.
So all the topics listed are important and useful. But it is not clear how they can covered these many topics in a meaningful way in one day (the course goes from 8:30 AM to 4:30 PM). But clearly, these statistical concepts are useful for the food industry. Presumably the fees for the attendees are paid for by their employers. In any case, this short course demonstrates the importance of statistics in the food industry. More importantly, it demonstrate to anyone taking an introductory stats course that what they are learning in class can open up a world of new ideas and opportunities.
Here’s the description of the course on sensory evaluation.
Course: Sensory Evaluation

This course is a hands-on course. The goal is to develop a greater understanding of the science behind food aroma, taste, color and texture, in other words, ways to make food products more enticing and appealing. The 4 bullets points list out the key objectives – learning about different tests that can be used and developing practical skills on setting up and running discrimination tests. Descriptive statistics (third bullet) is a bog topic – analyzing the data that are produced from the tests and experiments.
We are not endorsing the courses by any means. These courses provide a vivid example of applications in statistics, in this instance in food science. This post is a plug on statistics and not necessarily a plug on the entity that gives the courses.
______________________________________________________________
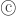 2017 – Dan Ma
2017 – Dan Ma